Introduction
Recent technology advances in high-density, byte-addressable non-volatile memory (NVM) and low-latency interconnects have enabled building large-scale systems with a large disaggregated fabric-attached memory (FAM) pool shared across heterogeneous and decentralized compute nodes. In this model, compute nodes are decoupled from FAM, which allows separate evolution and scaling of processing and memory. Thus, the compute-to-memory ratio can be tailored to the specific needs of the workload. Compute nodes fail independently of FAM, and these separate fault domains provide a partial failure model that avoids a complete system shutdown in the event of a component failure. When a compute node fails, updates propagated to FAM remain visible to other compute nodes.
The traditional shared-nothing model of distributed computing partitions data between compute nodes. Each compute node "owns" its local data and relies on heavyweight two-sided message passing and data copying to coordinate with other nodes. Data owners mediate access to their data, performing work on behalf of the requester. This model suffers mediation overheads and doesn't sufficiently leverage the data sharing potential of FAM systems.
In contrast, the large capacity of the FAM pool means that large working sets can be maintained as in-memory data structures. The fact that all compute nodes share a common view of memory means that data sharing and communication may be done efficiently through shared memory, without requiring explicit messages to be sent over heavyweight network protocol stacks. Additionally, data sets no longer need to be partitioned between compute nodes, as is typically done in clustered environments and avoid message-based coordination overheads. Any compute node can operate on any part of data, which enables more dynamic and flexible load balancing. More generally, sharing permits new approaches to cooperation.
OpenFAM is an application programming interface (API) for use in systems that contain FAM. The API is close to and is patterned after APIs provided by one-sided partitioned global address space (PGAS) libraries such as OpenSHMEM. This maintains ease of use for application writers already familiar with those libraries. The primary distinctions between this API and those provided by other PGAS libraries are:
- FAM is no longer associated with a specific PE, and can be addressed directly from any PE without the cooperation and/or involvement of any other PE.
- Because state in FAM can survive program termination, additional interfaces are present to manage FAM data beyond the lifetime of a single program.
- The independence of state maintained in FAM provides additional capability for managing application availability in the presence of component failure.
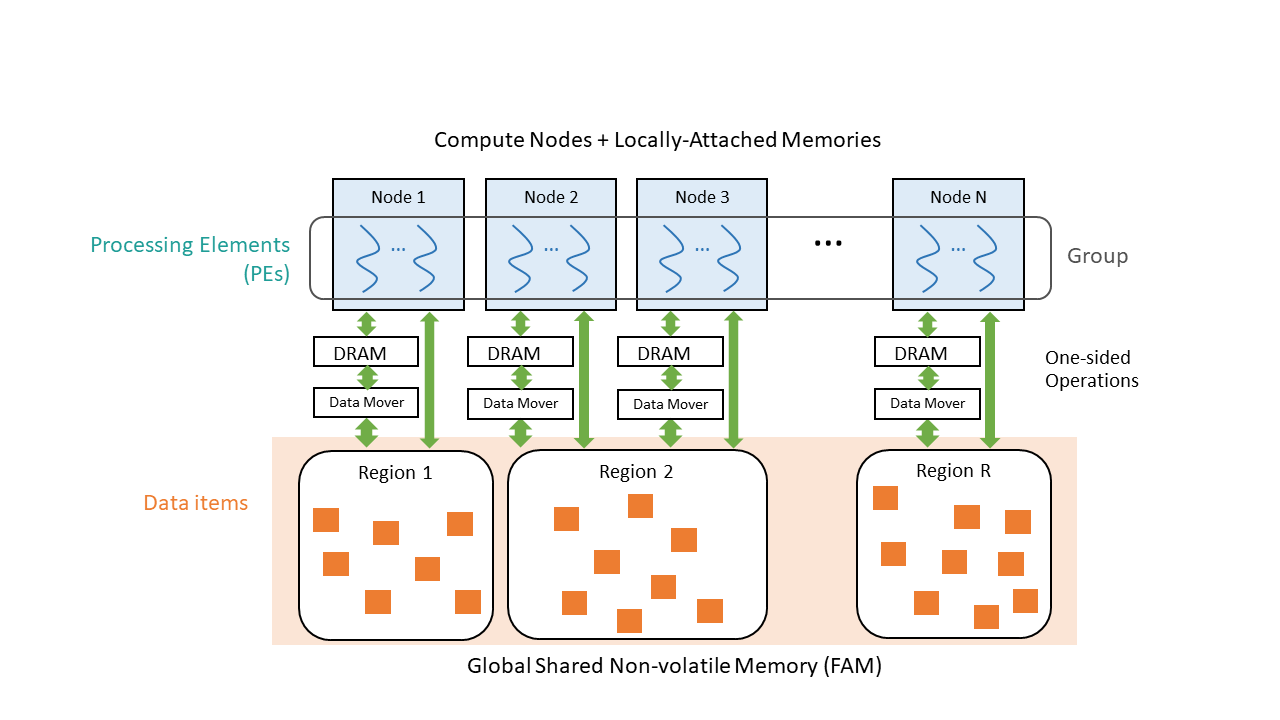
Figure 1 shows the system model assumed in OpenFAM. The system provides a multi-OS environment where each compute node runs a separate operating system instance, with locally attached memory that is "private" to the OS instance. Programmable data movers support efficient high-speed movement of data between local memory and FAM at a hardware level, as well as atomic operations on FAM. To distinguish references to the two types of memory, we use the term FAM to refer to fabric-attached memory and local memory to refer to the DRAM (or persistent memory) attached locally to a processing node. We also assume in the API that FAM may be persistent to enable data to be shared not only within a running program, but also across program instances in larger computational workflows.
The application spans compute nodes, and is composed of a group of processing elements (PEs) that cooperate with one another. Each processing element represents a thread of execution that uses both local memory and FAM to perform its tasks. FAM acts as a shared persistent space where PEs may place and access data. As in other PGAS programming models, we assume that the application is responsible for coordination of accesses between PEs to any shared data and for managing data consistency in FAM.
The implementation manages FAM in a two level hierarchy. At the coarser level programs can create FAM regions, which are large blocks of memory. Regions may have non-functional properties (e.g., resilience or security properties) associated with them. Regions have names, which can be used by the programmer to get handles (descriptors) to them. At the more granular level, memory managers can allocate data items within the regions. Data items inherit the non-functional characteristics of the regions within which they are allocated.
FAM is addressed by descriptors, which are opaque read-only data structures within applications, and contain sufficient information in them to uniquely locate the corresponding region or data item in FAM. In addition to FAM addresses, descriptors also include access permissions for the underlying regions and data items. Currently, the API supports UNIX®-like permissions for access control to any data item that is long-lived. It leaves open the possibility of using secret authentication tokens, key pairs, or even PKI-based certificates for access control based on security needs to the implementation. A name service is used to maintain mappings from user-friendly names to descriptors that locate data in FAM. Currently, the API leaves the structure of names open. In line with the two-level memory hierarchy represented by regions and data items, the implementation assumes that all regions within FAM have unique names, and data items within a given region are also named uniquely. If a hierarchical name space is desirable, it can be accommodated within the name service implementation with no modifications of the API.
While the OpenFAM API can be implemented in different languages, the reference implementation provides C and C++ bindings. Extensions to other languages are straightforward and can be provided in the future. Variable and method names in the API use underscore separated lower-case words. Data types start with initial upper case letters, while method names and method arguments start with lower case, as do fields within data types. To maintain separation from other programs, all type and method names have the prefix “Fam_” or “fam_” depending on whether the name represents a data type or a method name. Where multiple methods have the same functionality, and the method signature is also identical, we use the C convention of adding “_TYPE” as a suffix to separate out the methods.
The reference implementation of OpenFAM can be found here.